ArtifactLens: Hundreds of Labels Are Enough for Artifact Detection with VLMs
Preprint
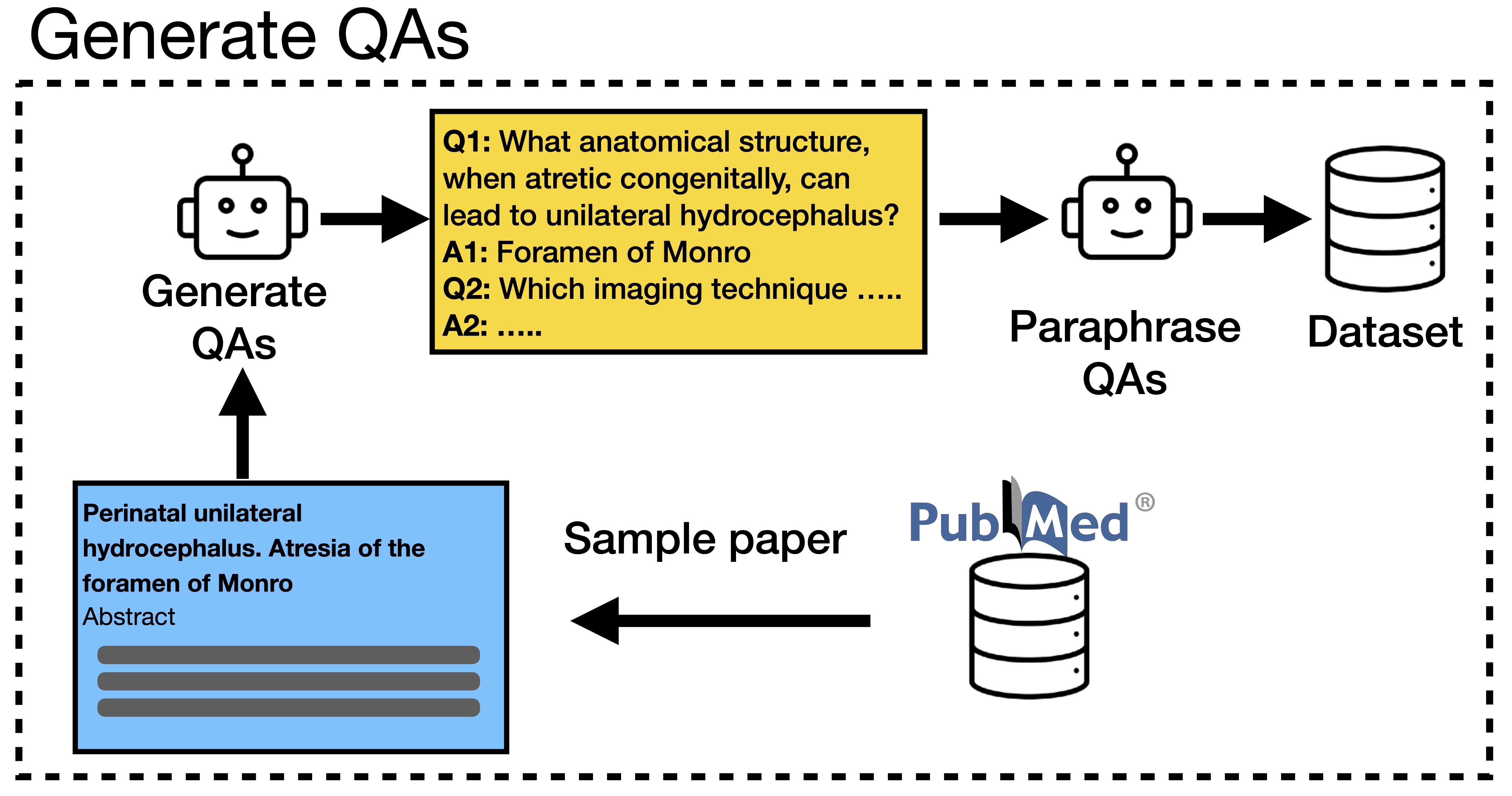
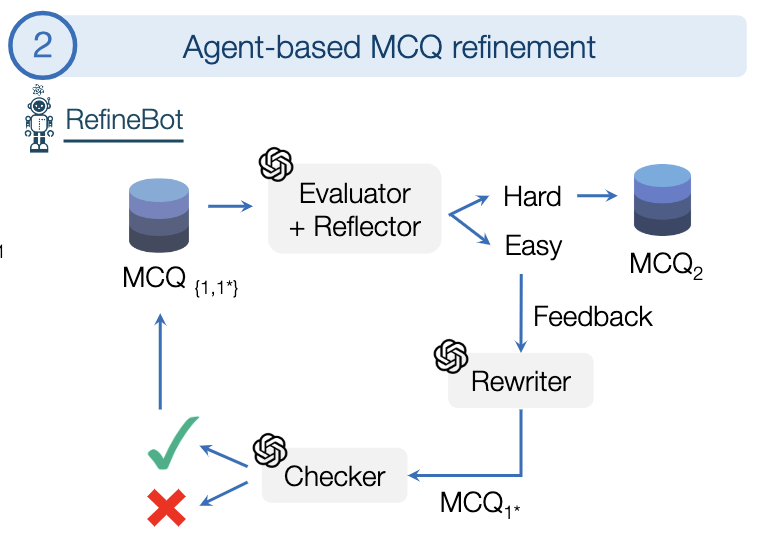
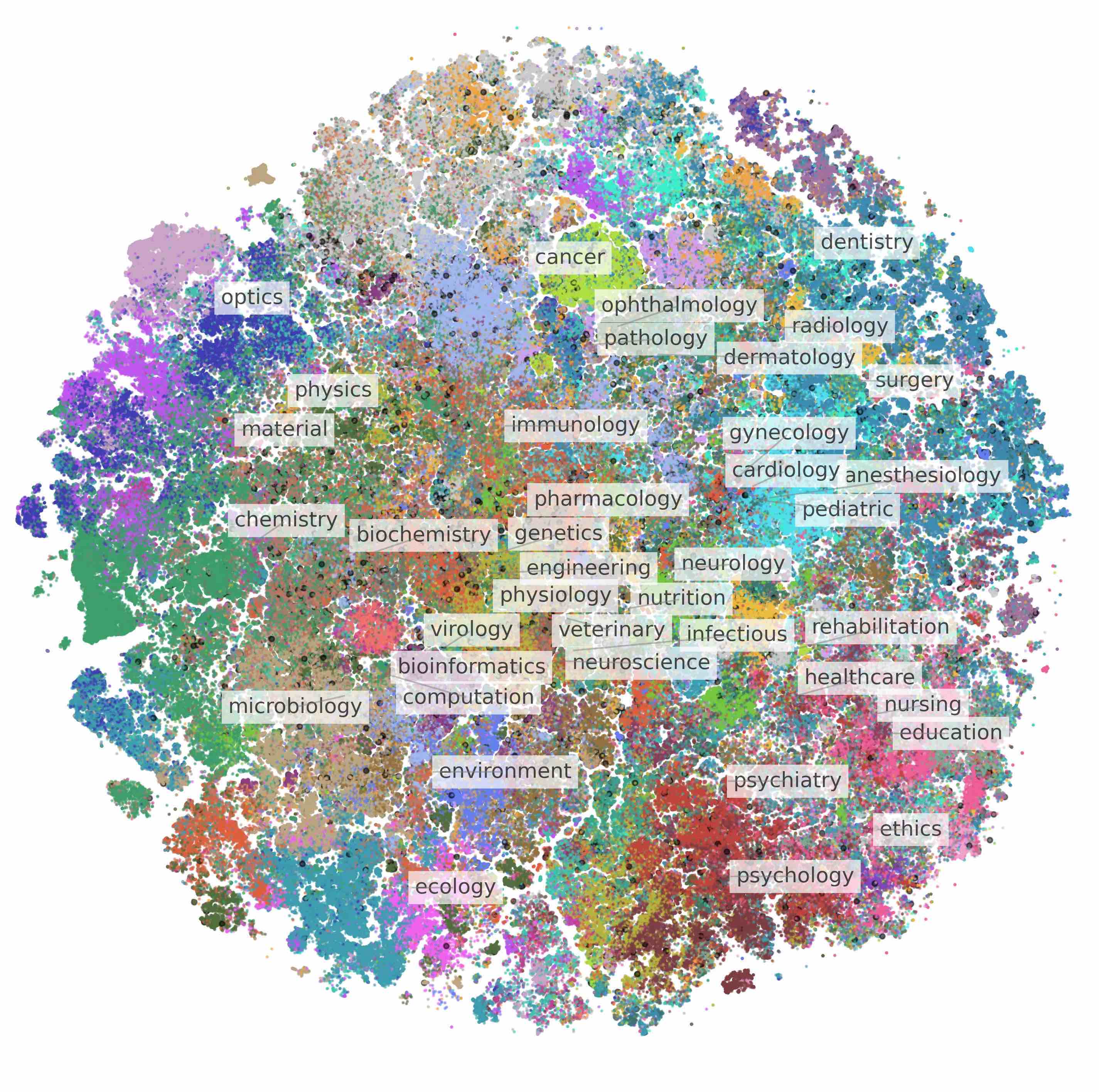
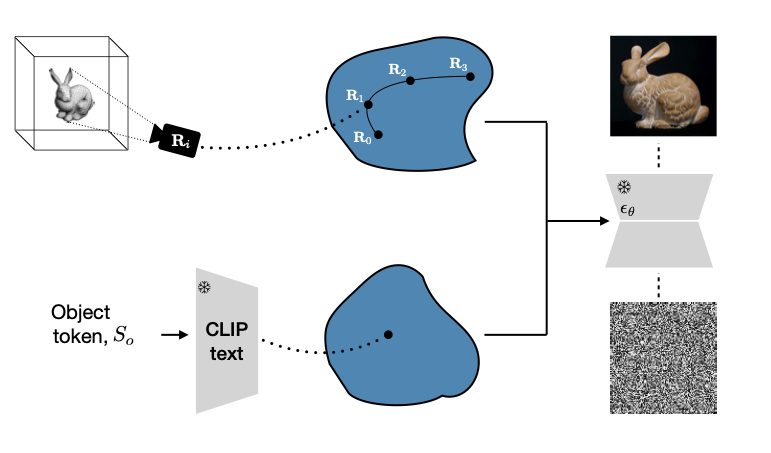
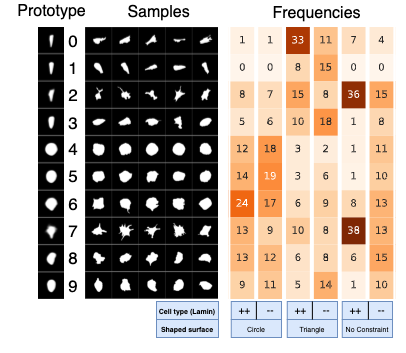
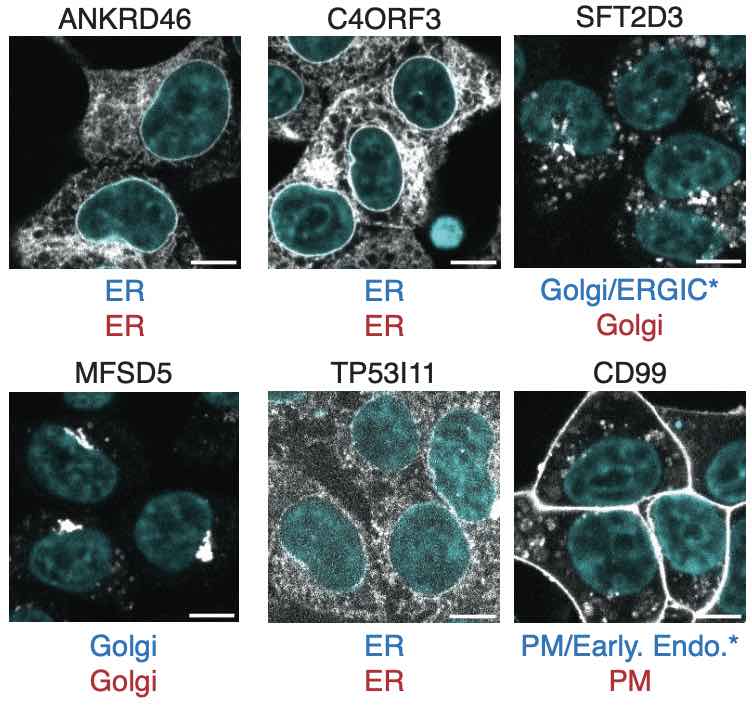
Detecting artifacts in AI-generated images can improve generators. Older works fine-tune VLMs, but we find that scaffolding with small datasets (hundreds) can be enough. Key tools: in-context learning, prompt optimization, and multi-component design.